d:swarm – Data Management and Swarm Intelligence
We have accomplished an important milestone in our sub-project Data Management Platform. We are proud to present the alpha release and, at the same time, pronounce the name of our data integration and data modelling tool: d:swarm. This name does call to mind associations with swarm intelligence, busy swarming and altruistic collaboration. At this stage, however, we focus on making our principal idea of a highly flexible data integration solution with a graphical user interface come true. We want to take away the task of data management from programmers and IT specialists and give it back into the hands of those to whom it belongs: librarians, metadata experts and knowledge workers.
These are the people whom we address with our semi-public alpha release of d:swarm. Please help us test our web application using all your knowledge about data and data transformation requirements. This way we can – at this early stage – strive to comply with them and develop a tool that is, at the same time, generic enough and adjustable to your or your institution’s individual needs so you can really use it.
Form Follows Function
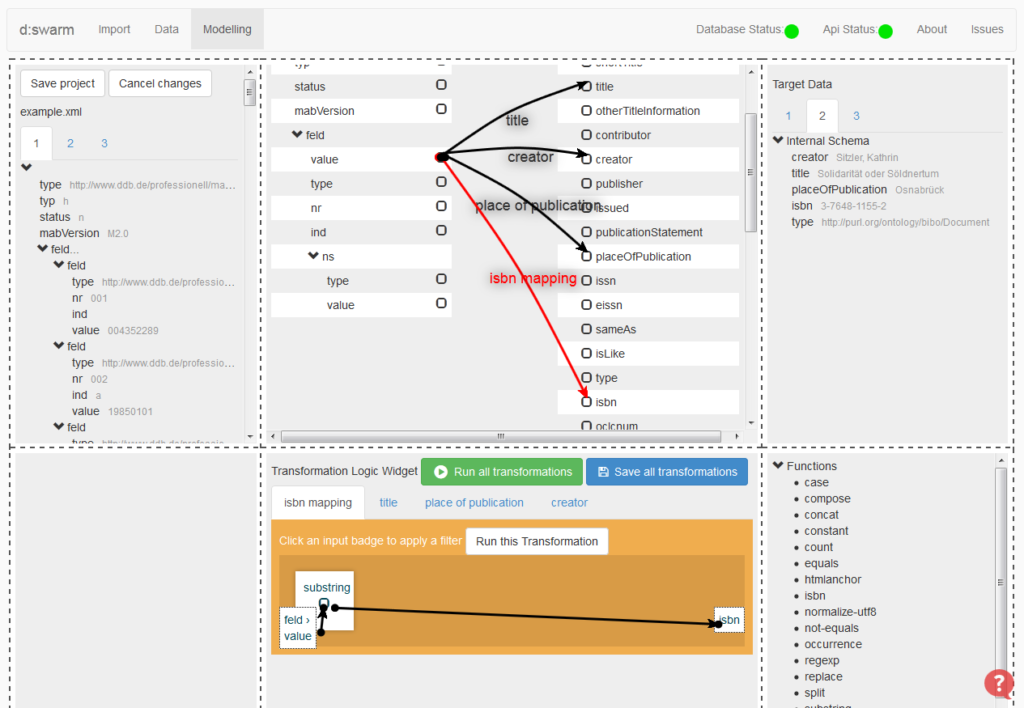
Beauty is not our primary ambition with the alpha release. We like a visually aesthetic web page, but this will come later: Our design ideas as far as the GUI is concerned have not yet been implemented. Our first concern is, at this stage, a proof of concept that the integration and management of data of different formats, some of them being a structural pain like MARCXML, and from a variety of sources is possible using a flexible tool like d:swarm.
Managing metadata of resources in a way so as to enable new dimensions in the retrieval of information is the main goal of d:swarm. An example from the practice of library data management: Currently it is extremely difficult, if not impossible, to retrieve a comprehensive list of currently published German academic journals in order to, for instance, analyse their citation frequency in Web of Science or Scopus or to make a statement about German as a scholarly language. Don’t get us wrong, the data is out there: In the ZDB catalogue, THE authoritative catalogue of journals in the German-speaking areas, the publication history of journals is recorded. Unfortunately, it is neither machine-readable nor indexed, so a traditional database query will not yield any reasonable result. Problems also arise if one is interested in the language journals are published in internationally. While it is possible to filter your search using the country of publication, there is usually no language information available with the journal titles. Also, the question as to the scientific importance of a journal might pose a problem. It can be judged by a look at its subject classification. To express this question as a database query is, however, next to impossible.
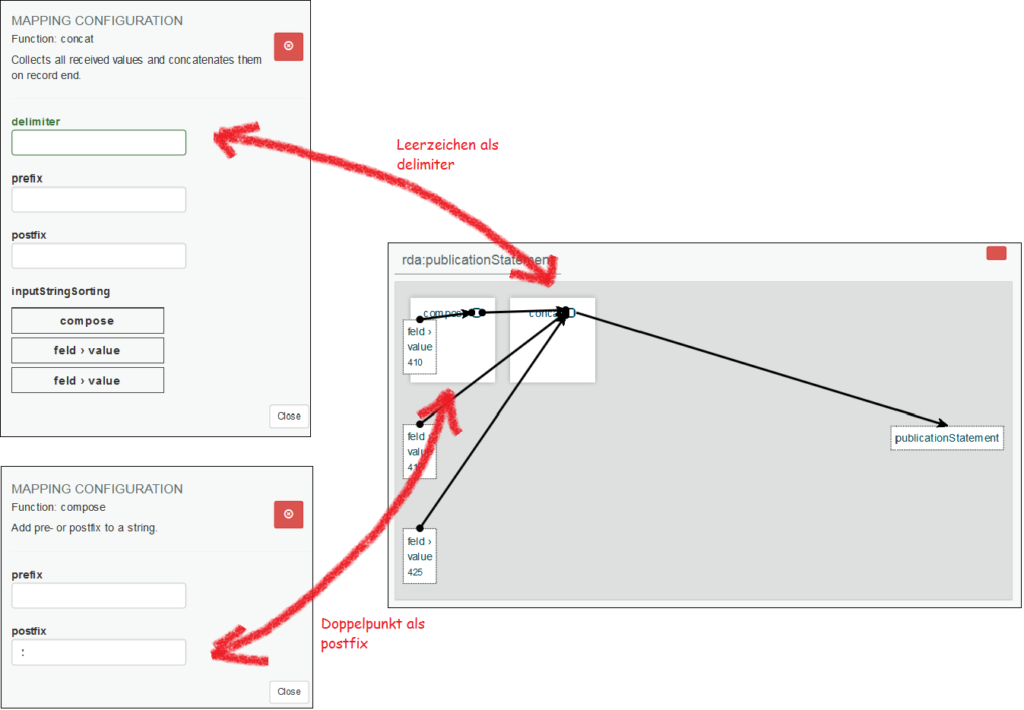
An viable solution for the problem of insufficient retrieval capabilities goes by the name of intelligent data integration and Linked Data. If we turn away from the currently widely practised record-based management of metadata to an object-centered approach, we can guarantee a significantly improved retrievability of information just because of the fact that practically any query can be articulated for our metadata. In this approach every single piece of information is a resource that is linked in a more or less complex way with any other resource. The storage format for data of this kind is, of course, a graph. That is why we implement a graph data model as the internal storage format of d:swarm. In the alpha release it is a hard-coded format based on the DINI specifications for the RDF representation of bibliographic data. In the future, the internal data format will be configurable using a schema editor.
Of Graphs and Linked Open Data
We have chosen the open-source graph database Neo4j as the data storage solution for d:swarm. This solution is getting more and more popular in the community. For us, it is interesting not just because it is flexible but also because it has a nice built-in visualization tool that makes graph exploration impressively exciting.
Testers who are interested in exploring the data structures in the data hub of d:swarm are invited to do so. You will find a short tutorial in our documentation. To be able to generate Linked Open Data out of the data as it is presented here, is a fundamental requirement in our approach which makes it differ from other approaches. Our motto is “Get out of the data silo!”, and if we pursue the idea of Linked Open Data in the Cultural Heritage area generally and in the area of bibliographic data specifically, we will arrive at a complete obsolescence, of library, archive or museum data silos, local or global.
How You Can Help
Our web application is available at http://sdvdswarm01.slub-dresden.de. If you want to participate in the alpha tests, drop us a note, and we will gladly add you to the group of testers. We are looking forward to your feedback, your ideas, and your opinion.