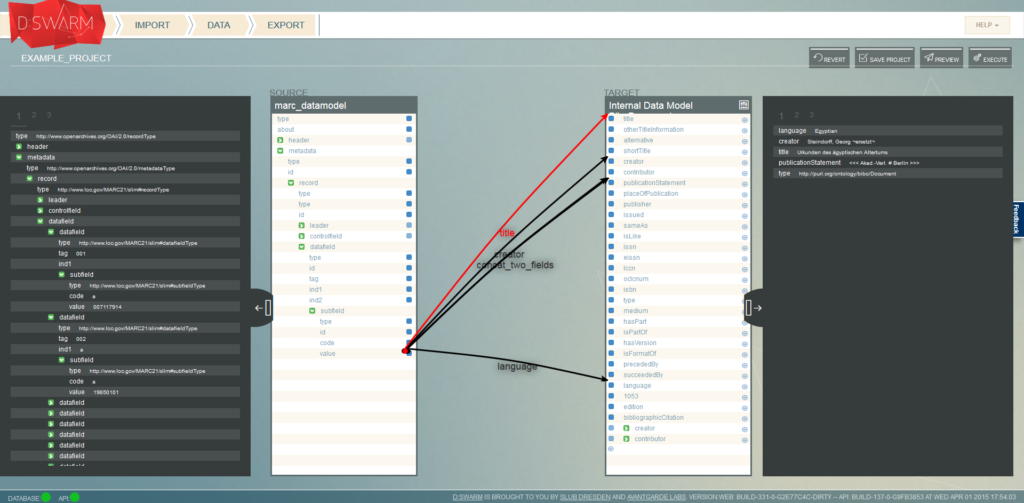
d:swarm is a data management platform that can be used for lossless transformation of data from heterogeneous sources into a flexible (elastic) data model. This data model can serve as a single source for feeding search engine indices or providing Linked Open Data (LOD).
d:swarm is a middle ware solution. It forms the basis of all data management processes especially in libraries or any other (cultural) institutions dedicated to the handling of data and metadata. Generally, d:swarm can be applied an any other domain as well. Structurally, d:swarm goes in between existing data management systems (e.g. Integrated Library Systems) and existing front end applications (e.g. the library catalogue or discovery system).
d:swarm is a data management platform that can be used for lossless transformation of data from heterogeneous sources into a flexible (elastic) data model. This data model can serve as a single source for feeding search engine indices or providing Linked Open Data (LOD).
d:swarm is a middle ware solution. It forms the basis of all data management processes especially in libraries or any other (cultural) institutions dedicated to the handling of data and metadata. Generally, d:swarm can be applied an any other domain as well. Structurally, d:swarm goes in between existing data management systems (e.g. Integrated Library Systems) and existing front end applications (e.g. the library catalogue or discovery system).
Finally, d:swarm is an ETL tool with a GUI intended for knowledge workers, e.g., system librarians. Librarians do not need to write scripts, however can map attributes from a source via Drag and Drop to an arbitrary target schema. Furthermore, those mappings can be enhanced by complex transformations via Drag and Drop from a functions library. d:swarm is realized as a web application that runs in all modern web browsers.