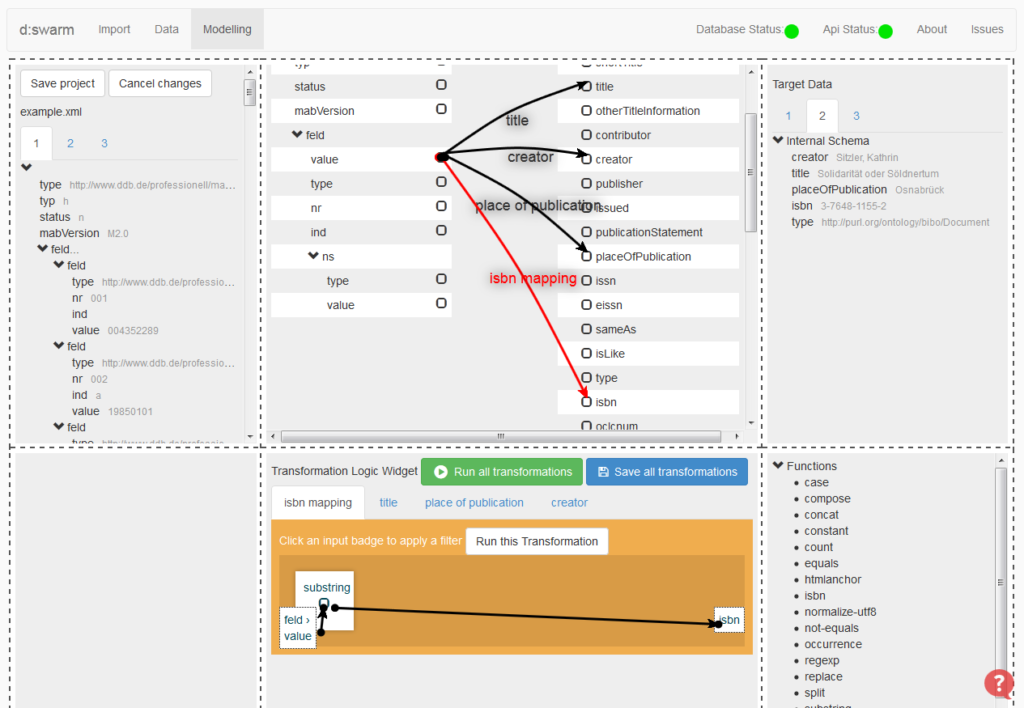
We are happy to bring you (yet) another version of d:swarm with many new and interesting features. Furthermore, d:swarm is successfully deployed and in production mode at SLUB Dresden right now. Since our last release @ ELAG 2015 wasn’t announced officially via this channel here, we also try to list the changes that have been made between our last official release from April 2015 up to now.
So here is the list of features that have been added or enhanced since our last release(s):
- JSON import
- extend support of inbuilt schemata, e.g.,
- OAI-PMH + DC Terms, OAI-PMH + DC Elements, OAI-PMH + MARCXML, PNX, MARCXML, MABXML (since ELAG 2015 release)
- OAI-PMH + DC Elements + Europeana (since v0.9.1)
- task processing “on-the-fly” (streaming variant via Task Processing Unit (TPU) + streaming enabled at d:swarm backend):
- enables a large(r) scale data processing at an acceptable amount of time
- mappings can be taken from multiple projects
- TPU tasks can be executed in parallel threads, when a data source is split into multiple chunks
- XML can be exported on-the-fly (i.e. the result of the task processing is not stored centrally in the Data Hub)
- input schemata can be re-utilised (e.g. useful for CSV data)
- new transformation functions:
- regex map lookup (regexlookup): a lookup map that allows regular expression as keys
- dewey validating/parsing (dewey)
- HTTP API request function (http-api-request)
- JSON parse function (parse-json)
- (real) collect function (collect)
- numeric filter (numfilter)
- ISSN validation/parsing (issn)
- convert value (convert-value): to be able to create, e.g., resources (instead of literals) as object
- enhanced transformation functions:
- SQL map (sqlmap)
- new filter functions:
- numeric filter
- equals
- not-equals
- (regex was default)
- skip filter: for whole job, i.e., only records that match the criteria of the filter will be emitted
- record search/selection: to be able to execute preview/test tasks @ Backoffice with specific records
- various maintenance/productivity improvements, e.g.,
- copy mappings (to new project with input data model with very similar schema, e.g., a schema that was generated by given example data to an inbuilt schema)
- migrate mappings (to new project with input data model with somehow similar schema, e.g., OAI-PMH MARCXML to MARCXML)
- enhanced error handling/ more expressive logging + more expressive messages for user
- various bug fixes and improvements over all parts of the application (frontend, backend, graph extension, …)
- XML enhancing step (experimental)
- (deprecate data model (backend only))
- (deprecate records in a data model (backend only))
- scale Data Hub (mainly optimize storage footprint + re-write some indexing approaches)
- transformation logic widget (arrow drawing) has been redesigned
Feel free to test all these additions, improvements and enhancements at our demo instance. We are happy about any kind of feedback via our various communication channels: Twitter, Gitter, Google+, mailing list, issue tracker or simply drop us a note at team[at]dswarm[dot]org.
Happy testing and evaluating!